Distributed System
1、服务治理
1.1 负载均衡
1.2 熔断、降级
2、服务通信
2.1 RPC
2.2 Netty
-
+
游客
注册
登录
熔断、降级
当我们的系统整体访问量突然激增,大量的请求在瞬间涌入,或者某个下游服务突然异常,大量请求调用阻塞,这个时候,为了保证系统核心业务能正常提供功能,我们可以采取一下三种措施,分比为**限流**、**熔断**、**降级**,这三种措施又被称为**高可用的三大利器**。 ## 1 限流 ### 1.1 含义 1. 在不同场景下限流的定义也各不相同,可以是**每秒请求数**、**每秒事务数**、**网络流量**,通常我们所说的限流指的是**限制到达系统并发请求数**,**使得系统能够正常的处理部分用户的请求**,**来保证系统的稳定性**。 2. 当接口的请求数达到限流的条件时,可进行以下行为: 1. **拒绝服务**:**把多出来的请求拒绝掉**。 2. **服务降级**:**把后端服务做降级处理**,这样**可以让服务有足够的资源来处理更多的请求**。 3. **特权请求**:**资源不够了**,**我们只能把有限的资源分给重要的用户**。 4. **延时处理**:**一般会有一个队列来缓冲大量的请求**,**这个队列如果满了**,**那么就只能拒绝用户了**,**如果这个队列中的任务超时了**,**可以返回系统繁忙的错误**。 5. **弹性伸缩**:**用自动化运维的方式对相应的服务做自动化的伸缩**。 ### 1.2 限流算法 常见的限流算法有两大类,分别是**计数器限流**、**桶限流**。 #### 1.2.1 计数器限流 计数器限流算法分为两种,分比为**固定时间窗口计数器**和**滑动时间窗口计数器**。 ##### 1.2.1.1 固定时间窗口计数器 ###### 1.2.1.1.1 含义 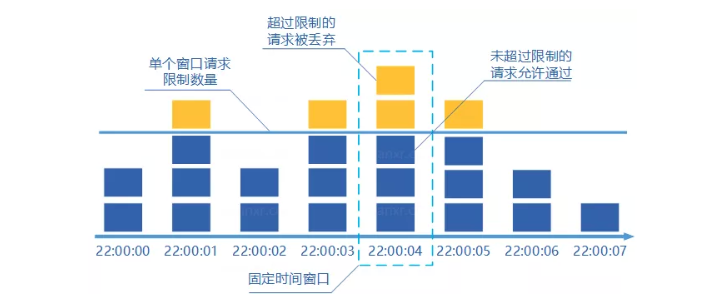 1. 固定时间窗口计数器算法是指**将时间按照设定的周期划分为多个窗口**,**在当前时间窗口内每来一次请求就将计数器加 1**,**如果计数器超过了限制数量**,**则拒绝服务**,**当时间到达下一个窗口时**,**计数器的值会重置**。 ###### 1.2.1.1.2 优缺点 1. **优点**: 1. **实现简单**,**占用内存小**,**只需要存储时间窗口中的计数即可**。 2. **缺点**: 1. **流量曲线不够平滑**,**有突刺现象**: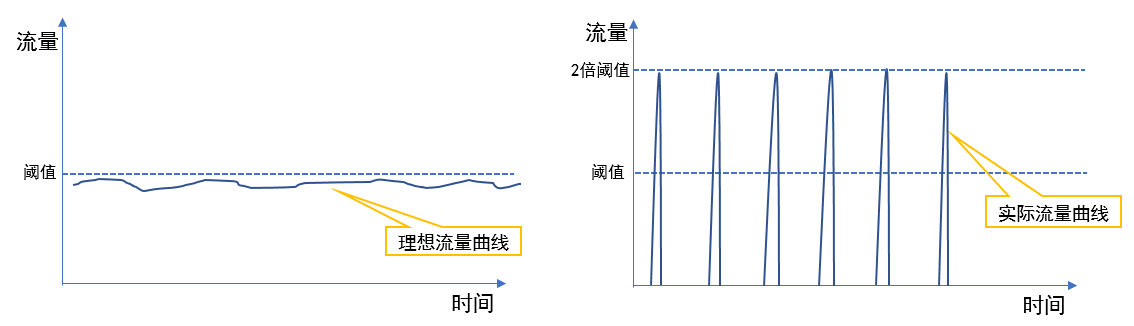 1. **一段时间内**(不超过时间窗口)**系统服务不可用**:比如窗口大小为 1s,限流大小为 100,然后恰好在某个窗口的第 1ms 来了 100 个请求,然后第 2ms 到 999ms 的请求都会被拒绝,这段时间用户会感觉系统服务不可用。 2. **窗口切换时可能会产生两倍于阈值流量的请求**,即**瞬时流量的临界问题**,**在最坏的情况下**,**会让通过的请求量是限制数量的两倍**:比如窗口大小为 1s,限流大小为 100,然后恰好在某个窗口的第 999ms 来了 100 个请求,窗口前期没有请求,所以这 100 个请求都会通过,再恰好,下一个窗口的第 1ms 又来了 100 个请求,也全部通过了,也就是在 2ms 内通过了 200 个请求,而我们设定的阈值是 100,通过的请求达到了阈值的两倍。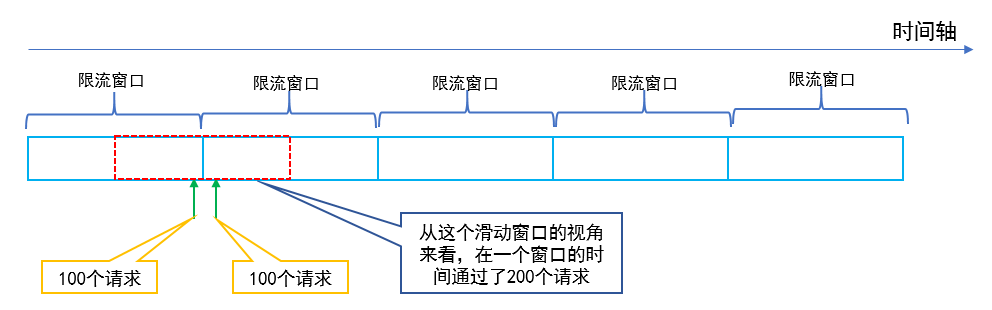 ###### 1.2.1.1.2 实现 1. **单机版本**: ```java /** * 一个时间窗口内最大请求数(限流最大请求数) */ private static final Long MAX_NUM_REQUEST = 2L; /** * 一个时间窗口时间(毫秒)(限流时间) */ private static final Long TIME_REQUEST = 1000L; /** * 一个时间窗口内请求的数量累计(限流请求数累计) */ private AtomicInteger requestNum = new AtomicInteger(0); /** * 一个时间窗口开始时间(限流开始时间) */ private AtomicLong requestTime = new AtomicLong(System.currentTimeMillis()); public String index() { // 当前时间 long nowTime = System.currentTimeMillis(); // 判断是否在当前时间窗口 if (nowTime < requestTime.longValue() + TIME_REQUEST) { // 判断是否达到最大限流请求数 if (requestNum.longValue() < MAX_NUM_REQUEST) { // 在时间窗口内,且没有达到最大限流请求数,请求数 +1 requestNum.incrementAndGet(); String msg = String.format("请求成功,当前请求是 %s 次", requestNum.longValue()); log.info(msg); return msg; } } else { // 超时后重置,开启一个新的时间窗口 requestTime = new AtomicLong(nowTime); requestNum = new AtomicInteger(1); String msg = String.format("请求成功,当前请求是 %s 次", requestNum.longValue()); log.info(msg); return msg; } requestNum.incrementAndGet(); String msg = String.format("请求失败,被限流,当前请求是 %s 次", requestNum.longValue()); log.info(msg); return msg; } ``` 2. **分布式版本**: > 分布式版本一般是借助 Redis + Lua 来实现。 1. **秒极限流**(每秒限制多少请求): ```lua -- 实现原理 -- 每次请求都将当前时间,精确到秒作为 key 放入 Redis 中 -- 超时时间设置为 2s, Redis 将该 key 的值进行自增 -- 当达到阈值时返回错误,表示请求被限流 -- 写入 Redis 的操作用 Lua 脚本来完成 -- 利用 Redis 的单线程机制可以保证每个 Redis 请求的原子性 -- 资源唯一标志位 local key = KEYS[1] -- 限流大小 local limit = tonumber(ARGV[1]) -- 获取当前流量大小 local currentLimit = tonumber(redis.call('get', key) or "0") if currentLimit + 1 > limit then -- 达到限流大小 返回 return 0; else -- 没有达到阈值 value + 1 redis.call("INCRBY", key, 1) -- 设置过期时间 redis.call("EXPIRE", key, 2) return currentLimit + 1 end ``` 2. **自定义参数限流**(自定义多少时间限制多少请求): ```lua -- 实现原理 -- 每次请求都去 Redis 取到当前限流开始时间和限流累计请求数 -- 判断限流开始时间加超时时间戳(限流时间)大于当前请求时间戳 -- 再判断当前时间窗口请求内是否超过限流最大请求数 -- 当达到阈值时返回错误,表示请求被限流,否则通过 -- 写入 Redis 的操作用 Lua 脚本来完成 -- 利用 Redis 的单线程机制可以保证每个 Redis 请求的原子性 -- 一个时间窗口开始时间(限流开始时间)key 名称 local timeKey = KEYS[1] -- 一个时间窗口内请求的数量累计(限流累计请求数)key 名称 local requestKey = KEYS[2] -- 限流大小,限流最大请求数 local maxRequest = tonumber(ARGV[1]) -- 当前请求时间戳 local nowTime = tonumber(ARGV[2]) -- 超时时间戳,一个时间窗口时间(毫秒)(限流时间) local timeRequest = tonumber(ARGV[3]) -- 获取限流开始时间,不存在为 0 local currentTime = tonumber(redis.call('get', timeKey) or "0") -- 获取限流累计请求数,不存在为 0 local currentRequest = tonumber(redis.call('get', requestKey) or "0") -- 判断当前请求时间戳是不是在当前时间窗口中 -- 限流开始时间加超时时间戳(限流时间)大于当前请求时间戳 if currentTime + timeRequest > nowTime then -- 判断当前时间窗口请求内是否超过限流最大请求数 if currentRequest + 1 > maxRequest then -- 在时间窗口内且超过限流最大请求数,返回 return 0; else -- 在时间窗口内且请求数没超,请求数加一 redis.call("INCRBY", requestKey, 1) return currentRequest + 1; end else -- 超时后重置,开启一个新的时间窗口 redis.call('set', timeKey, nowTime) redis.call('set', requestKey, '0') -- 设置过期时间 redis.call("EXPIRE", timeKey, timeRequest / 1000) redis.call("EXPIRE", requestKey, timeRequest / 1000) -- 请求数加一 redis.call("INCRBY", requestKey, 1) return 1; end ``` ##### 1.2.1.2 滑动时间窗口计数器 ###### 1.2.1.2.1 含义 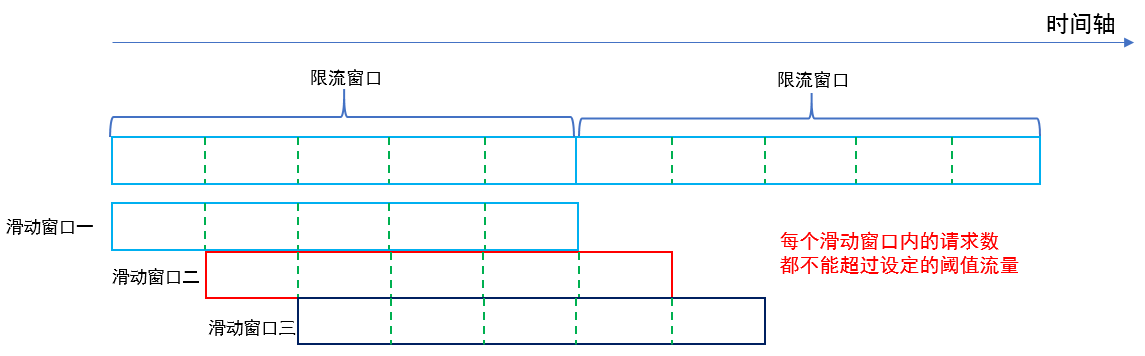 1. 滑动时间窗口计数器算法**是固定时间窗口计数器算法的改进**,**解决了固定时间窗口切换时可能会产生两倍于阈值流量请求的缺点**,**TCP 协议中数据包的传输**,**同样也是采用滑动窗口来进行流量控制**。 2. 滑动时间窗口算法**在固定时间窗口的基础上**,**将一个计时窗口分成了若干个小窗口**,然后**每个小窗口维护一个独立的计数器**,**每进入一个请求则将计数器加 1**。 3. **当请求的时间大于当前窗口的最大时间时**,**将计时窗口向前平移一个小窗口**,**平移时**,**将第一个小窗口的数据丢弃**,然后**将第二个小窗口设置为第一个小窗口**,同时**在最后面新增一个小窗口**,**将新的请求放在新增的小窗口中**,**同时要保证整个窗口中所有小窗口的请求数目之和不能超过设定的阈值**。 4. **滑动时间窗口算法就是固定时间窗口的升级版**,**将计时窗口划分成一个小窗口**,**滑动时间窗口就退化成了固定时间窗口算法**,而**滑动时间窗口算法其实就是对请求数进行了更细粒度的限流**,**窗口划分的越多**,则**限流越精准**。 5. 具体示例如下: 1. 如下图所示,我们把每分钟分为三份,每个小格是 20 秒,对每个小格都会分别计数: 1. `00:00:00 ~ 00:00:20`:访问 2 次。 2. `00:00:20 ~ 00:00:40`:访问 2 次。 3. `00:00:40 ~ 00:01:00`:访问 116 次。 4. `00:01:00 ~ 00:01:20`:访问 116 次。 2. 第一次统计,我们先看 `00:00:00 ~ 00:01:00`,计数 120 次,没有超过流量限制,然而在下一个 20 秒中,流量请求集中,在 `00:00:00 ~ 00:01:20` 这一分钟的统计范围内,流量超过了限制,则可以限制访问。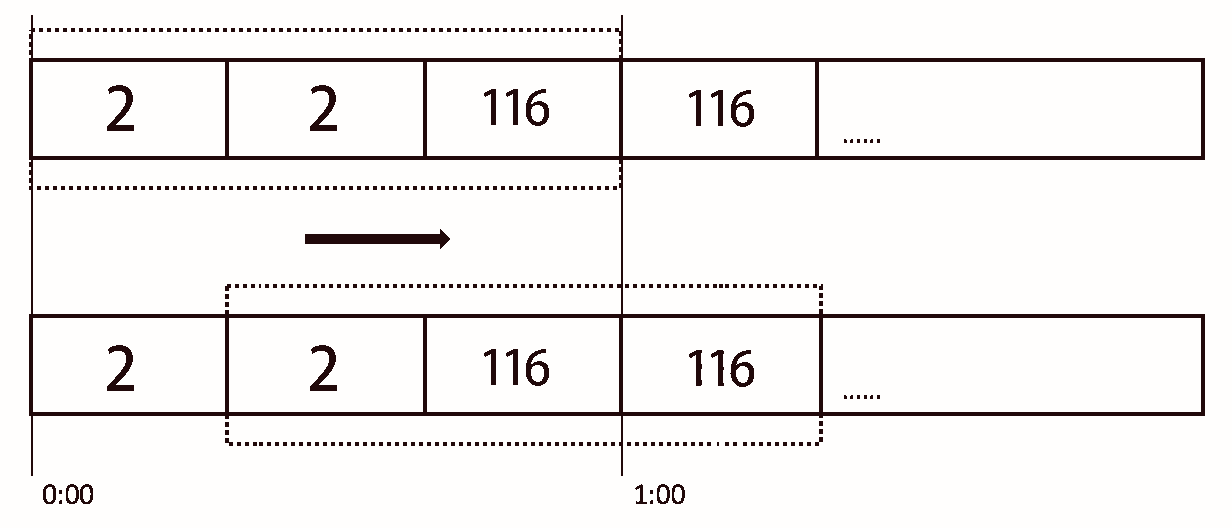 ###### 1.2.1.2.2 优缺点 1. **优点**: 1. **避免了固定时间计数器算法窗口切换时可能会产生两倍于阈值流量请求的问题**。 2. **缺点**: 1. **当窗口流量到达阈值时**,**流量会瞬间切断**,但是**在实际应用中**,**我们想要的限流效果往往不是把流量一下子切断**,**而是让流量平滑地进入系统当中**。 2. **窗口划分的越多**,**限流越精准**,但是**内存占用也会越多**。 ###### 1.2.1.2.3 实现 1. **单机版本**: ```java private int windowSize; //窗口大小,毫秒为单位 private int limit;//窗口内限流大小 private int splitNum;//切分小窗口的数目大小 private int[] counters;//每个小窗口的计数数组 private int index;//当前小窗口计数器的索引 private long startTime;//窗口开始时间 private CounterSildeWindowLimiter(){} public CounterSildeWindowLimiter(int windowSize, int limit, int splitNum){ this.limit = limit; this.windowSize = windowSize; this.splitNum = splitNum; counters = new int[splitNum]; index = 0; startTime = System.currentTimeMillis(); } //请求到达后先调用本方法,若返回 true,则请求通过,否则限流 public synchronized boolean tryAcquire(){ long curTime = System.currentTimeMillis(); long windowsNum = Math.max(curTime - windowSize - startTime,0) / (windowSize / splitNum);//计算滑动小窗口的数量 slideWindow(windowsNum);//滑动窗口 int count = 0; for(int i = 0;i < splitNum;i ++){ count += counters[i]; } if(count >= limit){ return false; }else{ counters[index] ++; return true; } } private synchronized void slideWindow(long windowsNum){ if(windowsNum == 0) return; long slideNum = Math.min(windowsNum,splitNum); for(int i = 0;i < slideNum;i ++){ index = (index + 1) % splitNum; counters[index] = 0; } startTime = startTime + windowsNum * (windowSize / splitNum);//更新滑动窗口时间 } ``` 2. **分布式版本**: > 分布式版本一般是借助 Redis + Lua 来实现。 ```lua local token = KEYS[1] local now = tonumber(ARGV[1]) local window = tonumber(ARGV[2]) local limit = tonumber(ARGV[3]) local clearBefore = now - window redis.call('ZREMRANGEBYSCORE', token, 0, clearBefore) local amount = redis.call('ZCARD', token) if amount < limit then redis.call('ZADD', token, now, now) end redis.call('EXPIRE', token, window) return limit - amount ``` #### 1.2.2 桶限流 1. 上面提到的两种基于时间窗口的限流算法(**固定时间窗口计数器算法**和**滑动时间窗口计数器算法**)都**无法应对细时间粒度的突发流量**,**对流量的限制效果在细时间粒度上不够平滑**。 2. 下面介绍两种基于桶的更加平滑的限流算法(**漏斗算法**和**令牌桶算法**),在某些场景下,这两种算法**优于时间窗口算法成为首选**。 ##### 1.2.2.1 漏斗算法 ###### 1.2.2.1.1 含义 1. 漏斗算法的原理为**请求来了之后会先放进漏斗里**,然后**以恒定的速率将请求流出**进行处理,从而起到**平滑流量**的作用。 2. 当**请求的流量过大**时,漏斗**达到最大容量时会溢出**,此时**请求被丢弃**。 3. 从系统角度看,我们**不知道什么时候会有请求来**,**也不知道请求会以多大的速率来**,这就**给系统的安全性埋下了隐患**,但是**加了一层漏斗算法限流之后**,就**能够保证请求以恒定的速率流出**,在系统看来,**请求永远是以平滑的传输速率过来**,从而起到**保护系统**的作用。 4. 漏斗算法**一般用于保护第三方的系统**,**比如自身的系统需要调用第三方的接口**,**为了保护第三方的系统不被自身的调用打垮**,**便可以通过漏斗算法进行限流**,**保证自身的流量平稳的打到第三方的接口上**。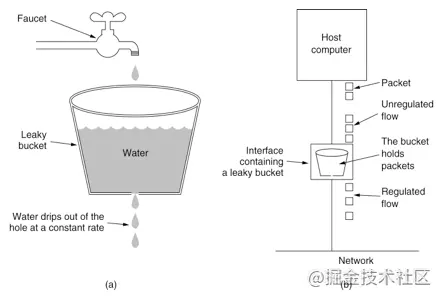 ###### 1.2.2.1.2 优缺点 1. **优点**: 1. **漏斗的漏出速率是固定的**,**可以起到整流的作用**:即虽然请求的流量可能具有随机性,忽大忽小,但是经过漏斗算法之后,变成了有固定速率的稳定流量,从而对下游的系统起到保护作用。 2. **缺点**: 1. **不能解决流量突发的问题**:假如漏斗的容量是 5,设定的漏斗速率是 2 个/秒,然后突然来了 10 个请求,受限于漏斗的容量,只有 5 个请求被接受,另外 5 个被拒绝,接收的 5 个请求只是被接受了,但是没有被马上处理,处理的速度依然是我们设定的 2 个/秒,所以没有解决流量突发的问题。 ###### 1.2.2.1.3 实现 1. **单机版本**: ```java private int capaticy;//漏斗容量 private int rate;//漏斗速率 private int left;//剩余容量 private LinkedList<Request> requestList; private LeakyBucketLimiter() {} public LeakyBucketLimiter(int capaticy, int rate) { this.capaticy = capaticy; this.rate = rate; this.left = capaticy; requestList = new LinkedList<>(); //开启一个定时线程,以固定的速率将漏斗中的请求流出,进行处理 new Thread(new Runnable() { @Override public void run() { while(true){ if(!requestList.isEmpty()){ Request request = requestList.removeFirst(); handleRequest(request); } try { Thread.sleep(1000 / rate); //睡眠 } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); } /** * 处理请求 * @param request */ private void handleRequest(Request request){ request.setHandleTime(new Date()); System.out.println(request.getCode() + "号请求被处理,请求发起时间:" + request.getLaunchTime() + ",请求处理时间:" + request.getHandleTime() + ",处理耗时:" + (request.getHandleTime().getTime() - request.getLaunchTime().getTime()) + "ms"); } public synchronized boolean tryAcquire(Request request){ if(left <= 0){ return false; }else{ left --; requestList.addLast(request); return true; } } /** * 请求类,属性包含编号字符串、请求达到时间和请求处理时间 */ static class Request{ private int code; private Date launchTime; private Date handleTime; private Request() { } public Request(int code,Date launchTime) { this.launchTime = launchTime; this.code = code; } public int getCode() { return code; } public void setCode(int code) { this.code = code; } public Date getLaunchTime() { return launchTime; } public void setLaunchTime(Date launchTime) { this.launchTime = launchTime; } public Date getHandleTime() { return handleTime; } public void setHandleTime(Date handleTime) { this.handleTime = handleTime; } } ``` 2. **分布式版本**: > 分布式版本一般是借助 Redis + Lua 来实现。 ```lua local token = KEYS[1] local now = tonumber(ARGV[1]) local rate = tonumber(ARGV[2]) local capacity = tonumber(ARGV[3]) local lastTime = tonumber(redis.call('HGET', token, 'last_time') or 0) local tokensPend = tonumber(redis.call('HGET', token, 'tokens_pend') or 0) tokensPend = math.max(0, tokensPend - (now - lastTime) * rate) redis.call('HSET', token, 'last_time', now) if tokensPend < capacity then redis.call('HSET', token, 'tokens_pend', tokensPend + 1) return true end return false ``` ##### 1.2.2.2 令牌桶算法 ###### 1.2.2.2.1 含义 1. 令牌桶算法是**对漏斗算法的一种改进**,**除了能起到限流的作用**,**还允许一定程度的流量突发**。 2. **在令牌桶算法中**,**存在一个令牌桶**,**算法中存在一种机制以恒定的速率向令牌桶中放入令牌**,**令牌桶也有一定的容量**,**如果满了令牌就无法放进去了**。 3. **当请求来时**,**会首先到令牌桶中去拿令牌**,**如果拿到了令牌**,**则该请求会被处理**,**并消耗掉拿到的令牌**,**如果令牌桶为空**,**则该请求会被丢弃**。 4. 令牌桶算法**一般用于保护自身的系统**,**对调用者进行限流**,**保护自身的系统不被突发的流量打垮**,**如果自身的系统实际处理能力强于配置的流量限制时**,**可以允许一定程度的流量突发**,**使得实际的处理速率高于配置的速率**,**充分利用系统资源**。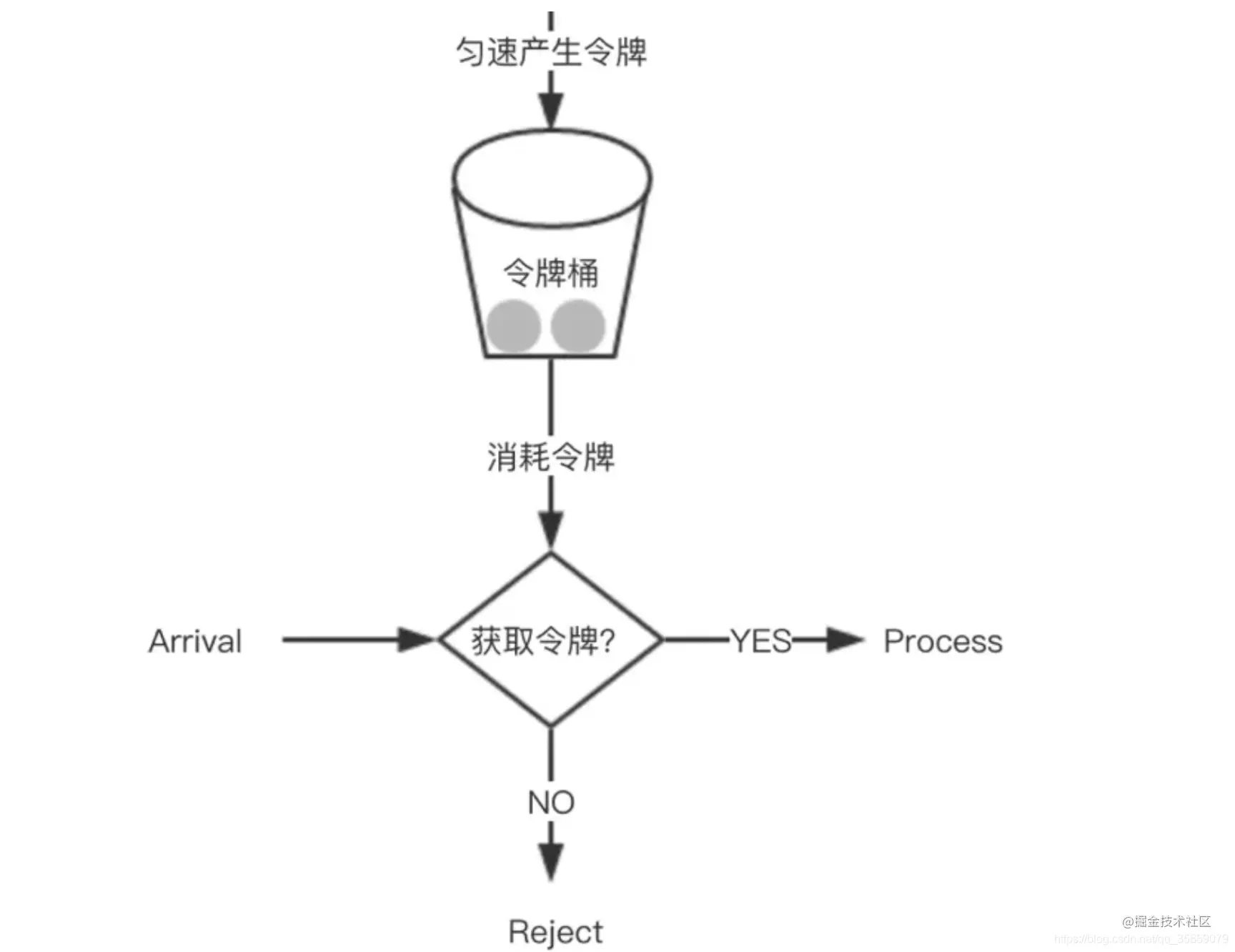 ###### 1.2.2.2.2 优缺点 1. **优点**: 1. 令牌桶算法**能够在限制调用的平均速率的同时还允许一定程度的流量突发**:假如令牌桶的容量是 5,设定的令牌桶产生令牌的速率是 2 个/秒,然后突然来了 10 个请求,与漏桶算法一样,都是接受了 5 个请求,拒绝了 5 个请求,与漏斗算法不同的是,令牌桶算法马上处理了这 5 个请求,处理速度可以认为是 5 个/秒,超过了我们设定的令牌桶产生令牌的速率,即允许一定程度的流量突发,这一点也是和漏斗算法的主要区别。 ###### 1.2.2.2.3 实现 1. ****单机版本**:** ```java private int capaticy;//令牌桶容量 private int rate;//令牌产生速率 private int tokenAmount;//令牌数量 public TokenBucketLimiter(int capaticy, int rate) { this.capaticy = capaticy; this.rate = rate; tokenAmount = capaticy; new Thread(new Runnable() { @Override public void run() { //以恒定速率放令牌 while (true){ synchronized (this){ tokenAmount ++; if(tokenAmount > capaticy){ tokenAmount = capaticy; } } try { Thread.sleep(1000 / rate); } catch (InterruptedException e) { e.printStackTrace(); } } } }).start(); } public synchronized boolean tryAcquire(Request request){ if(tokenAmount > 0){ tokenAmount --; handleRequest(request); return true; }else{ return false; } } /** * 处理请求 * @param request */ private void handleRequest(Request request){ request.setHandleTime(new Date()); System.out.println(request.getCode() + "号请求被处理,请求发起时间:" + request.getLaunchTime() + ",请求处理时间:" + request.getHandleTime() + ",处理耗时:" + (request.getHandleTime().getTime() - request.getLaunchTime().getTime()) + "ms"); } /** * 请求类,属性只包含一个名字字符串 */ static class Request{ private int code; private Date launchTime; private Date handleTime; private Request() { } public Request(int code,Date launchTime) { this.launchTime = launchTime; this.code = code; } public int getCode() { return code; } public void setCode(int code) { this.code = code; } public Date getLaunchTime() { return launchTime; } public void setLaunchTime(Date launchTime) { this.launchTime = launchTime; } public Date getHandleTime() { return handleTime; } public void setHandleTime(Date handleTime) { this.handleTime = handleTime; } } ``` 2. ****分布式版本**:** > 分布式版本一般是借助 Redis + Lua 来实现。 ```lua local token = KEYS[1] local now = tonumber(ARGV[1]) local rate = tonumber(ARGV[2]) local capacity = tonumber(ARGV[3]) local lastTime = tonumber(redis.call('HGET', token, 'last_time') or 0) local tokensLeft = tonumber(redis.call('HGET', token, 'tokens_left') or 0) tokensLeft = math.min(capacity, tokensLeft + (now - lastTime) * rate) redis.call('HSET', token, 'last_time', now) if tokensLeft >= 1 then redis.call('HSET', token, 'tokens_left', tokensLeft - 1) return true end return false ``` ## 参考文献 1. [熔断、降级和限流之间的区别](http://huhansi.com/2020/04/14/SpringCloud/2020-04-14-005-%E7%86%94%E6%96%AD%E3%80%81%E9%99%90%E6%B5%81%E5%92%8C%E9%99%8D%E7%BA%A7%E4%B9%8B%E5%89%8D%E7%9A%84%E5%8C%BA%E5%88%AB)。 2. [限流算法实践](https://www.infoq.cn/article/ipxnuqwu3lgwxc8j7tzw)。 3. [高并发下的限流分析](https://note.dolyw.com/distributed/02-Distributed-Limit.html)。 4. [分布式限流:基于 Redis 实现](https://pandaychen.github.io/2020/09/21/A-DISTRIBUTE-GOREDIS-RATELIMITER-ANALYSIS)。 5. [限流之固定窗口/滑动窗口计数法理解](https://blog.csdn.net/legend050709/article/details/114917637)。 6. [接口限流常用算法实践](https://rmingwang.com/api-rate-limiting-algorithm-practices.html)。 7. [一文搞懂高频面试题之限流算法,从算法原理到实现,再到对比分析](https://juejin.cn/post/6870396751178629127)。
ricear
2021年8月17日 16:39
©
BY-NC-ND(4.0)
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码