Netty
1、概述
2、线程模型
3、核心组件
3.1 Channel
3.2 ChannelHandler和ChannelPipeline
3.3 EventLoop和EventLoopGroup
3.4 Future和Promise
4、创建过程
4.1 服务端创建过程
4.2 客户端创建过程
5、TCP粘包和拆包
6、序列化与反序列化
-
+
游客
注册
登录
概述
## 1 Netty 是什么 Netty 是一款**异步的事件驱动的网络应用程序框架**,**支持快速地开发可维护的高性能的面向协议的服务器和客户端**。 ## 2 为什么要使用 Netty(原生 NIO 有什么问题) 1. **NIO 的类库和 API 复杂**,**使用麻烦**,我们需要熟练掌握 Selector、ServerSockerChannel、SocketChannel、ByteBuffer 等。 2. **需要具备其他的额外技能做铺垫**,例如熟悉 Java 多线程编程,这是因为 NIO 编程涉及到 Reactor 模式,我们必须对多线程和网络编程十分熟悉,才能编写出高质量的 NIO 程序。 3. **可靠性能力补齐**,**工作量和难度都非常大**,例如客户端面临断连重连、网络闪断、半包读写、失败缓存、网络拥塞和异常码流的处理等问题,NIO 编程的特点是功能开发相对容易,但是可靠性能力补齐的工作量和难度都非常大。 4. **JDK NIO 的 BUG**,例如臭名昭著的`epoll bug`,他会导致 Selector 空轮询,最终导致 CPU 100%,官方声称在 JDK 1.6 版本的`update18` 修复了该问题,但是直到 JDK 1.7 版本该问题仍旧存在,只不过该 BUG 发生概率低了一些而已,他并没有得到根本性解决。 5. 因此,**大多数场景下**,**不建议大家直接使用 JDK 的 NIO 类库**,除非我们精通 NIO 处理或者有特殊的需求,在大多数的业务场景中,我们**可以使用 NIO 框架的 Netty 来进行 NIO 编程**,**他既可以作为客户端**,**也可以作为服务端**,**同时支持 UDP 和异步文件传输**,**功能非常强大**。 ## 3 优缺点 ### 3.1 优点 1. **API 使用简单**,**开发门槛低**。 2. **功能强大**,**预置了多种编解码功能**,**支持多种主流协议**。 3. **定制能力强**,**可以通过 `ChannelHandler` 对通信框架进行灵活地扩展**。 4. **性能高**,**通过与其他业界主流的 NIO 框架对比**,**Netty 的综合性能最优**。 5. **成熟**、**稳定**,**Netty 修复了已经发现的所有 JDK NIO BUG**,**业务开发任务不需要再为 NIO 的 BUG 而烦恼**。 6. **社区活跃**,**版本迭代周期短**,**发现的 BUG 可以被及时修复**,**同时**,**更多的新功能会加入**。 7. **经历了大规模的商业应用考验**,**质量得到验证**,例如 Hadoop 的 RPC 框架 Avro 就使用了 Netty 作为底层通信框架。 ## 4 应用场景 1. **互联网行业**: 1. 在分布式系统中,各个节点间需要远程服务调用,高性能的[RPC](https://notebook.ricear.com/project-46/doc-836)框架必不可少,Netty 作为异步高性能的通信框架,往往作为**基础通信组件**被这些 RPC 框架使用。 2. 阿里分布式服务框架 Dubbo 的 RPC 框架使用 Dubbo 协议进行节点间通信,Dubbo 协议默认使用 Netty 作为基础通信组件,用于**实现个进程节点之间的内部通信**。 2. **游戏行业**: 1. 在手游服务端或者大型的网络游戏中,Netty 作为高性能的基础通信组件,**提供了 TCP/UDP 和 HTTP 协议栈**,**方便定制和开发私有协议栈**,**用于账号登录服务器**。 2. 同时,**地图服务器之间可以方便的通过 Netty 进行高性能的通信**。 3. **大数据领域**: 1. Hadoop 的高性能通信和序列化组件**Avro 的 RPC 框架**,**默认采用 Netty 进行跨节点通信**。 ## 5 特性 Netty 的高性能主要依赖于以下特性: 1. **异步非阻塞通信**。 2. **高效的 Reactor 线程模型**。 3. **无锁化的串行设计**。 4. **高性能的序列化框架**。 5. **零拷贝**。 ### 5.1 异步非阻塞通信 1. 在 I/O 编程过程中,当需要**同时处理多个客户端接入请求**时,可以**利用多线程或者[I/O 多路复用](https://notebook.ricear.com/project-26/doc-335/#3-3-IO-%E5%A4%9A%E8%B7%AF%E5%A4%8D%E7%94%A8)技术进行处理**。 2. I/O 多路复用技术通过**把多个 I/O 的阻塞复用到同一个 `select` 的阻塞上**,从而**使得系统在单线程的情况下可以同时处理多个客户端请求**。 3. 与传统的多线程/多进程模型比,I/O 多路复用的最大优势是**系统开销小**,系统**不需要创建新的额外进程或者线程**,**也不需要维护这些进程和线程的运行**,**降低了系统维护的工作量**,**节省了系统资源**。 4. Netty 的 I/O 线程[NioEventLoop](https://notebook.ricear.com/project-49/doc-850)由于**聚合了多路复用器 Selector**,**可以同时并发处理成百上千个客户端 SocketChannel**,由于**读写操作都是非阻塞的**,这就**可以充分提升 I/O 线程的运行效率**,**避免由于频繁的 I/O 阻塞导致的线程挂起**。 5. 同时,Netty**采用了异步通信模式**,**一个 I/O 线程可以并发处理 $N$ 个客户端连接和读写操作**,这**从根本上解决了传统同步阻塞 I/O 一连接一线程模型**,**架构的性能**、**弹性伸缩能力和可靠性都得到了极大的提升**。 ### 5.2 高效的 Reactor 线程模型 详见[2、线程模型](https://notebook.ricear.com/project-49/doc-846)。 ### 5.3 无锁化的串行设计 1. 在大多数场景下,**并行多线程处理可以提升系统的并发性能**,但是,**如果对于共享资源的并发访问处理不当**,**会带来严重的锁竞争**,这**最终会导致性能的下降**。 2. **为了尽可能地避免锁竞争带来的性能损耗**,**可以通过串行化设计**,即**消息的处理尽可能在同一个线程内完成**,**期间不进行线程切换**,这样就**避免了多线程竞争和同步锁**。 3. 从表面上看,**串行化设计似乎 CPU 利用率不高**,**并发度不够**,但是**通过调整 NIO 线程池的线程参数**,**可以同时启动多个串行化的线程并行运行**,这种**局部无锁化的设计相比一个队列来说性能更优**。 4. **为了尽可能提升性能**,**Netty 采用了串行无锁化设计**,**在 I/O 线程内部进行串行操作**,**避免多线程竞争导致的性能下降**,具体的工作原理如下图所示: 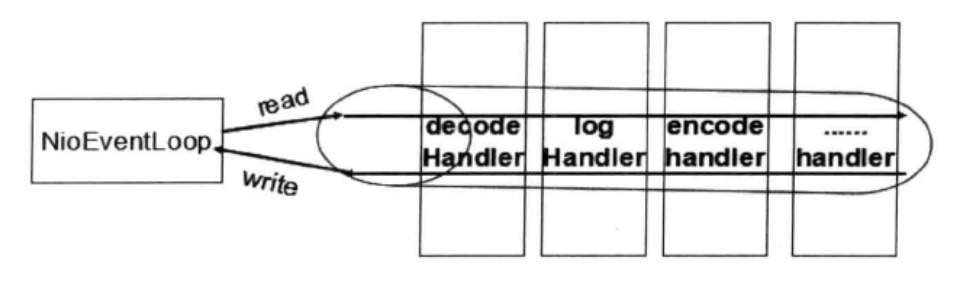 1. Netty 的 NioEventLoop 在**读取到消息之后**,**直接调用[ChannelPipeline](https://notebook.ricear.com/project-49/doc-848/#2-ChannelPipeline)的 `fireChannelRead()`**,**只要用户不主动切换线程**,**一直会由 NioEventLoop 调用到用户的 Handler**,**期间不进行线程切换**,**这种串行化的处理方式避免了多线程操作导致的锁竞争**,**从性能角度看是最优的**。 ### 5.4 高性能的序列化框架 1. 影响序列化性能的关键因素总结如下: 1. **序列化后的码流大小**(网络带宽的占用)。 2. **序列化和反序列化的性能**(CPU 资源占用)。 3. **是否支持跨语言**(异构系统的对接和开发语言切换)。 2. Netty**默认提供了对 Google Protobuf 的支持**,**通过扩展 Netty 的编解码接口**,**用户可以实现其他高性能的框架**。 3. 关于序列化框架的对比,可参考[4.1 框架设计](https://notebook.ricear.com/project-46/doc-836/#4-1-%E6%A1%86%E6%9E%B6%E8%AE%BE%E8%AE%A1)。 ### 5.5 零拷贝 #### 5.5.1 传统 Linux 中的零拷贝技术 1. 所谓零拷贝,就是**在数据操作时**,**不需要将数据从一个内存位置拷贝到另一个内存位置**,这样**可以减少一次内存拷贝的损耗**,从而**节省了 CPU 时钟周期和内存带宽**。 2. 例如,从文件中读取数据,然后将数据传输到网络上,传统的数据拷贝过程如下图所示: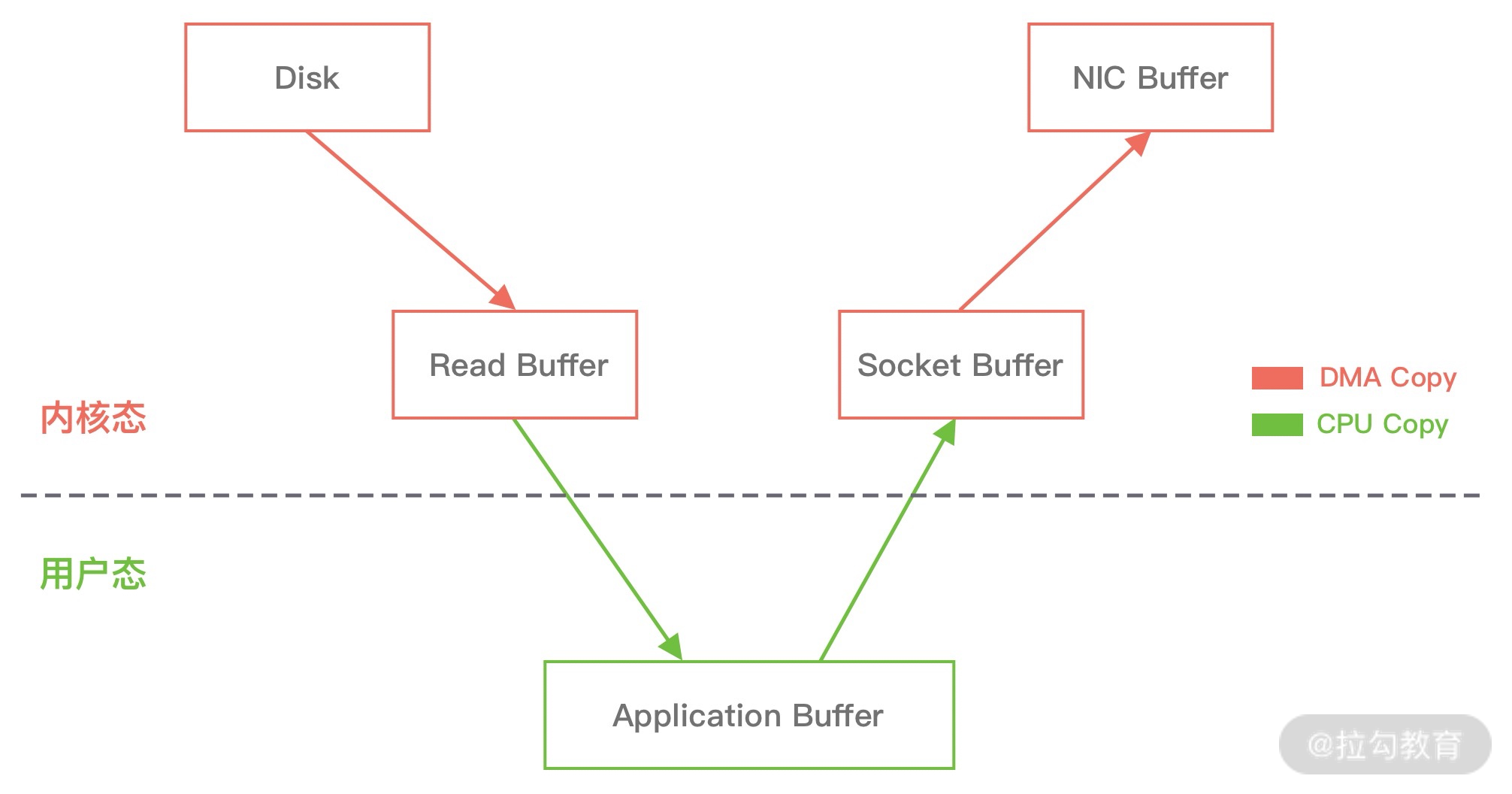 1. **当用户进程发起 `read()` 调用后**,**上下文从用户态切换到内核态**,**DMA 引擎从文件中读取数据**,并**存储到内核态缓冲区**,这是**第一次数据拷贝**。 2. **请求的数据从内核态缓冲区拷贝到用户态缓冲区**,然后**返回给用户进程**,**第二次数据拷贝的同时**,**会导致上下文从内核态再次切换到用户态**。 3. **用户进程调用 `send()` 方法期望将数据发送到网络中**,此时**会触发第三次线程切换**,**用户态会再次切换到内核态**,**请求的数据从用户态缓冲区被拷贝到 Socket 缓冲区**。 4. **最终 `send()` 系统调用结束返回给用户进程**,**发生了第四次上下文切换**,**第四次拷贝会异步执行**,**从 Socket 缓冲区拷贝到协议引擎中**。 > 1. 什么是 DMA?DMA,全称为 Direct Memory Access,即直接内存读取,是现代大部分硬盘都支持的特性,DMA 接管了数据读写的工作,不需要 CPU 再参与 I/O 中断的处理,从而减轻了 CPU 的负担。 > 2. 传统的数据拷贝过程为什么不是将数据直接传输到用户缓冲区呢? > > 其实引入内核缓冲区可以充当缓存的作用,这样就可以实现文件数据的预读,提升 I/O 的性能,但是当请求数据量大于内核缓冲区大小时,在完成一次数据的读取到发送可能要经历数倍次数的数据拷贝,这就造成严重的性能损耗。 > 3. 重新回顾一遍传统数据的拷贝过程,我们可以发现**第二次和第三次的数据拷贝是可以去除的**,**DMA 引擎从文件读取数据后放入到内核缓冲区**,**然后可以直接从内核缓冲区传输到 Socket 缓冲区**,**从而减少内存拷贝的次数**。 4. 在 Linux 中**系统调用 `sendfile()` 可以实现将数据从一个文件描述符传输到另一个文件描述符**,**从而实现零拷贝技术**。 5. 在 Java 中也使用了零拷贝技术,他就是 NIO 中**FileChannel 类的 `transferTo()` 方法**,其**底层依赖了操作系统零拷贝的机制**,**可以将数据从 FileChannel 直接传输到另外一个 Channel**,`transferTo()` 方法的定义如下: ```java public abstract long transferTo(long position, long count, WritableByteChannel target) throws IOException; ``` 在使用了 `FileChannel.transferTo()` 传输数据之后,数据拷贝流程发生了如下变化: 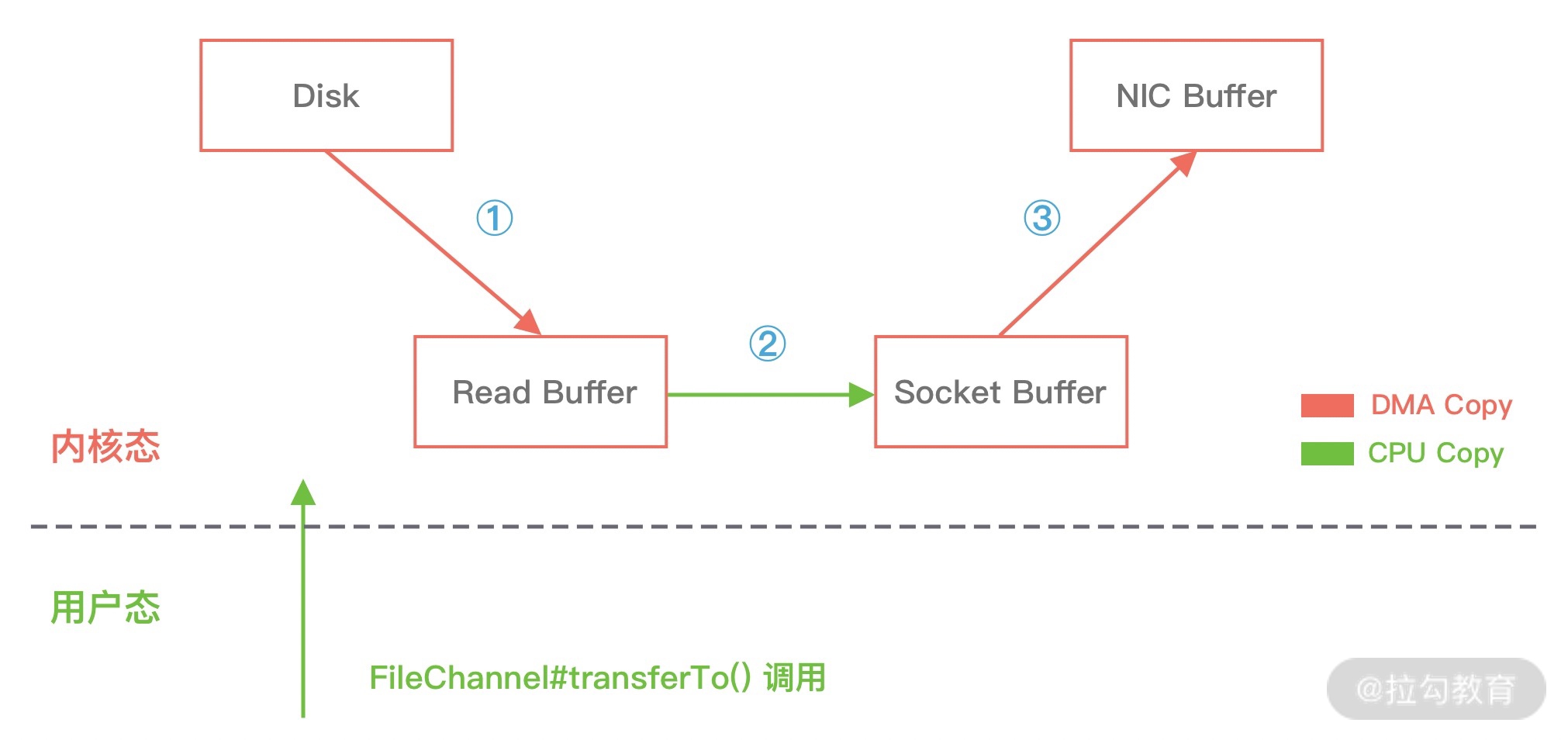 比较大的一个变化是**DMA 引擎从文件中读取数据拷贝到内核态缓冲区之后**,**由操作系统直接拷贝到 Socket 缓冲区**,**不再拷贝到用户态缓冲区**,所以**数据拷贝的次数从之前的 4 次减少到 3 次**。 6. 在**Linux 2.4 版本之后**,**开发者对 Socket Buffer 追加一些 Descripter 信息来进一步减少内核数据的复制**,如下图所示,**DMA 引擎读取文件内容并拷贝到内核缓冲区**,然而并**没有再拷贝到 Socket 缓冲区**,**只是将数据的长度以及位置信息被追加到 Socket 缓冲区**,然后**DMA 引擎根据这些描述信息**,**直接从内核缓冲区读取数据并传输到协议引擎中**,**从而消除最后一次 CPU 拷贝**: 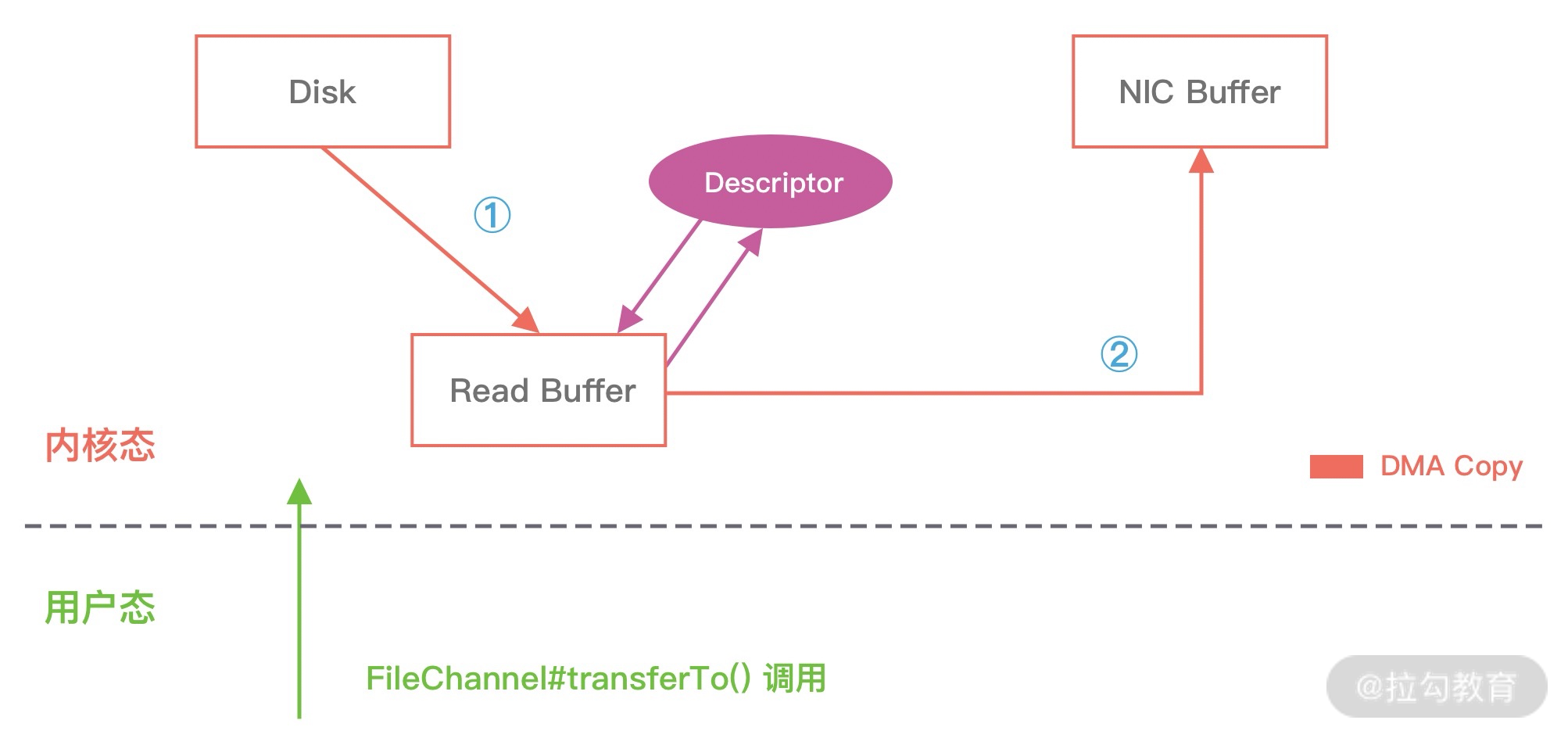 #### 5.5.2 Netty 的零拷贝技术 Netty 中的零拷贝和传统 Linux 的零拷贝不太一样,Netty 中的零拷贝技术**除了操作系统级别的功能封装**,**更多的是面向用户态的数据操作优化**,主要体现在一下 5 个方面: 1. **堆外内存**,**避免 JVM 堆内存到堆外内存的数据拷贝**。 2. **CompositeByteBuf 类**,**可以组合多个 Buffer 对象合并成一个逻辑上的对象**,**避免通过传统内存拷贝的方式将几个 Buffer 合并成一个大的 Buffer**。 3. **通过 `Unpooled.wrappedBuffer()` 可以将 `byte` 数组包装成 ByteBuf 对象**,**包装过程中不会产生内存拷贝**。 4. `ByteBuf.slice()`**操作与 `Unpooled.wrappedBuffer()` 相反**,`slice()`**操作可以将一个 ByteBuf 对象切分成多个 ByteBuf 对象**,**切分过程中不会产生内存拷贝**,**底层共享一个 `byte` 数组的存储空间**。 5. **Netty 使用 FileRegion 实现文件传输**,**FileRegion 底层封装了 `FileChannel.transferTo()` 方法**,**可以将文件缓冲区的数据直接传输到目标 Channel**,**避免内核缓冲区和用户缓冲区之间的数据拷贝**,这**属于操作系统级别的零拷贝**。 ##### 5.5.2.1 堆外内存 1. 如果**在 JVM 内部进行 I/O 操作**时,**必须将数据拷贝到[堆外内存](https://notebook.ricear.com/project-34/doc-541/#3-2-%E5%A0%86%E5%A4%96%E5%86%85%E5%AD%98-No-Heap-Memory-)**,**才能执行系统调用**,这**是所有 VM 语言都会存在的问题**。 2. 操作系统之所以不能直接使用 JVM 堆内存进行 I/O 读写,主要有两个原因: 1. **操作系统并不感知 JVM 的[堆内存](https://notebook.ricear.com/project-34/doc-541/#3-1-%E5%A0%86%E5%86%85%E5%AD%98-Heap-Memory-)**,而且**JVM 的内存布局与操作系统分配的是不一样的**,**操作系统并不会按照 JVM 的行为来读写数据**。 2. **同一个对象的内存地址随着 JVM GC 的执行可能会随时发生变化**,例如,JVM GC 的过程会通过压缩来减少内存碎片,这就涉及对象移动的问题了。 3. **Netty 在进行 I/O 操作时都是使用的堆外内存**,**可以避免数据从 JVM 堆内存到堆外内存的拷贝**。 ##### 5.5.2.2 CompositeByteBuf 1. CompositeButeBuf**是 Netty 中实现零拷贝机制非常重要的一个数据结构**,CompositeByteBuf**可以理解为一个虚拟的 Buffer 对象**,他**是由多个 ByteBuf 组合而成**,但是**在 CompositeByteBuf 内部保存着每个 ByteBuf 的引用关系**,**从逻辑上构成一个整体**,例如: 1. HTTP 协议数据可以分为头部信息 `header` 和消息体数据 `body`,分别存在两个不同的 ByteBuf 中。 2. 通常我们需要将两个 ByteBuf 合并成一个完整的协议数据进行发送: ```java ByteBuf httpBuf = Unpooled.buffer(header.readableBytes() + body.readableBytes()); httpBuf.writeBytes(header); httpBuf.writeBytes(body); ``` 可以看出,如果**想实现 `header` 和 `body` 这两个 ByteBuf 的合并**,**需要先初始化一个新的 ByteBuf**,然后再**将这 `header` 和 `body` 分别拷贝到新的 ByteBuf**,**合并过程涉及两次 CPU 拷贝**,这**非常浪费性能**。 3. 我们可以使用 CompositeByteBuf 来实现类似的需求: ```java CompositeByteBuf httpBuf = Unpooled.compositeBuffer(); httpBuf.addComponents(header, body); ``` 1. CompositeByteBuf**通过调用 `addComponents()` 方法来添加多个 ByteBuf**,但是**底层的 `byte` 数组是复用的**,**不会发生内存拷贝**,但**对于用户来说**,他**可以当做一个整体进行操作**。 2. CompositeByteBuf 的内部结构如下图所示: 1. 从图中可以看出,CompositeByteBuf**内部维护了一个 Components 数组**,**在每个 Component 中存放着不同的 ByteBuf**,**各个 ByteBuf 独立维护自己的读写索引**,而**CompositeByteBuf 自身也会单独维护一个读写索引**,由此可见,**Component 是实现 CompositeByteBuf 的关键所在**,其结构定义如下: ```java private static final class Component { final ByteBuf srcBuf; // 原始的 ByteBuf final ByteBuf buf; // srcBuf 去包装之后的 ByteBuf int srcAdjustment; // CompositeByteBuf 的起始索引相对于 srcBuf 读索引的偏移 int adjustment; // CompositeByteBuf 的起始索引相对于 buf 的读索引的偏移 int offset; // Component 相对于 CompositeByteBuf 的起始索引位置 int endOffset; // Component 相对于 CompositeByteBuf 的结束索引位置 Component(ByteBuf srcBuf, int srcOffset, ByteBuf buf, int bufOffset, int offset, int len, ByteBuf slice) { this.srcBuf = srcBuf; this.srcAdjustment = srcOffset - offset; this.buf = buf; this.adjustment = bufOffset - offset; this.offset = offset; this.endOffset = offset + len; this.slice = slice; } // ... 省略其他代码 } ``` 2. 为了方便理解上述 Component 中的属性含义,我们同样以 HTTP 协议中 `header` 和 `body` 为示例,通过一张图来描述 CompositeByteBuf 组合后其中 Component 的布局情况,如下图所示: 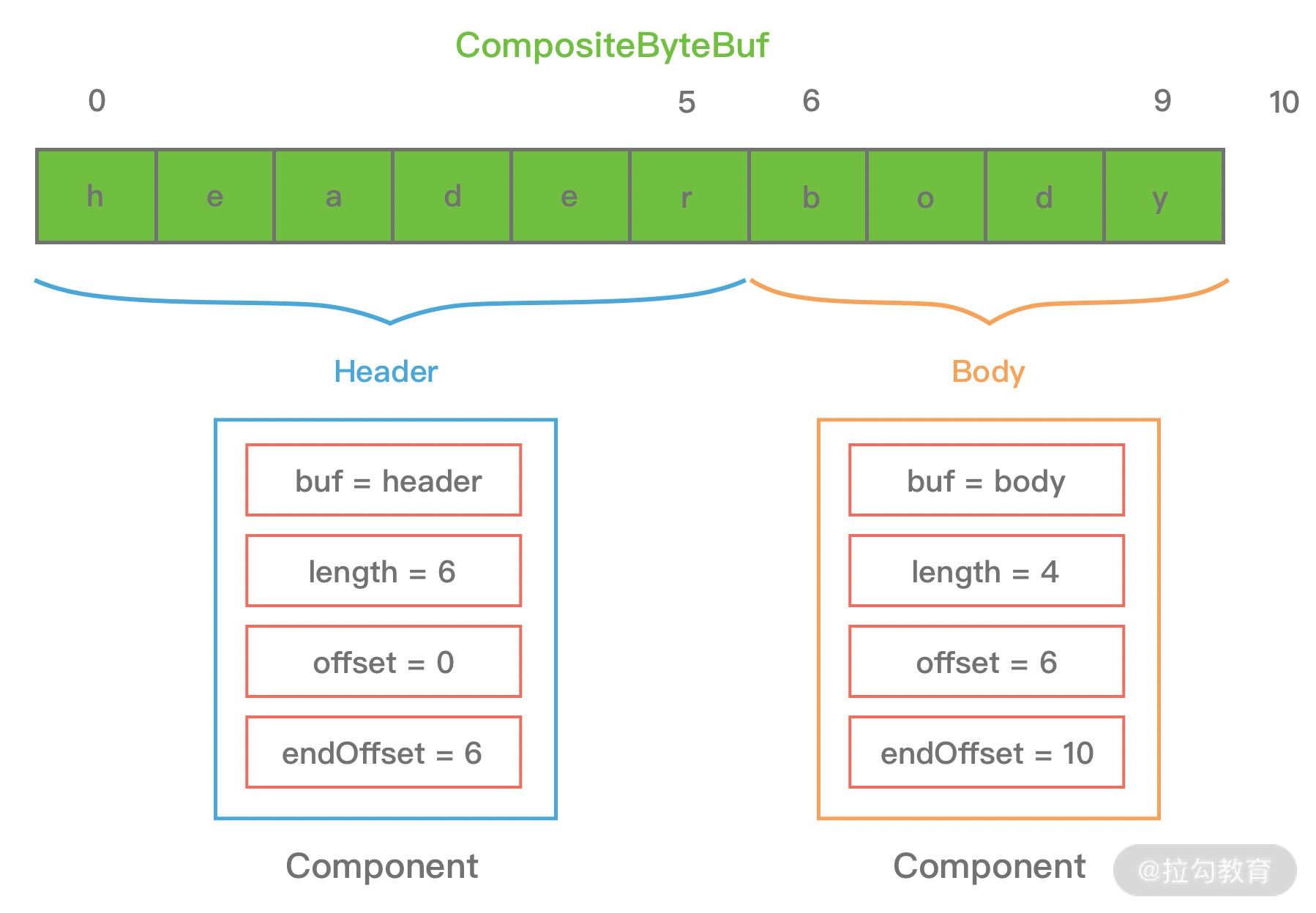 1. 此时从图中可以看出,`header` 和`body` 分别对应两个 ByteBuf,假设 ByteBuf 的内容分别为`header` 和`body`,那么`header` 中的`offset ~ endOffset` 为`0 ~ 6`,`body` 对应的`offset ~ endOffset` 为`6 ~ 10`,由此可见,Component 中的`offset`**和 `endOffset` 可以表示当前 ByteBuf 可以读取的范围**,**通过 `offset` 和 `endOffset` 可以将每一个 Component 所对应的 ByteBuf 连接起来**,**形成一个逻辑整体**。 2. 此外,Component 中`srcAdjustment`**和 `adjustment` 表示 CompositeByteBuf 起始索引相对于 ByteBuf 读索引的偏移**,**初始 `adjustment = readerIndex - offset`**,这样**通过 CompositeByteBuf 的起始索引就可以直接定位到 Component 中 ByteBuf 的读索引位置**,例如,当`header` 读取 1 个字节,`body` 读取 2 个字节,此时每个 Component 的属性如下图所示: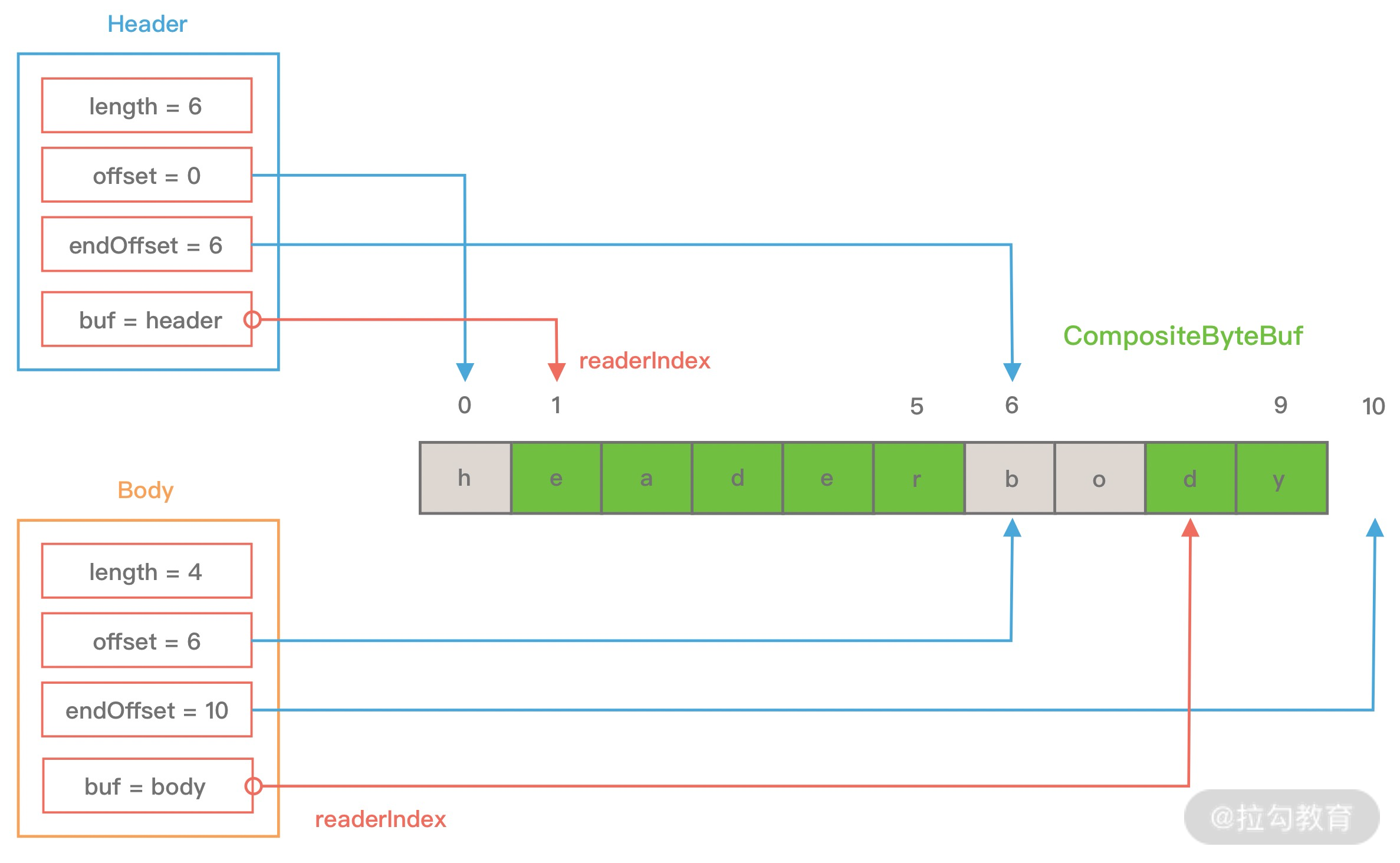 ##### 5.5.2.3 Unpooled.wrappedBuffer 1. Unpooled**提供了一系列用于包装数据源的 `wrappedBuffer` 方法**,该方法**可以将不同的数据源的一个或者多个数据包装成一个更大的 ByteBuf 对象**,**其中数据源的类型包括**`byte[]`、`ByteBuf`、`ByteBuffer`,**包装的过程中不会发生数据拷贝操作**,**包装后生成的 ByteBuf 对象和原始 ByteBuf 对象是共享底层的 `byte` 数组**。 ##### 5.5.2.4 ByteBuf.slice 操作 1. `Bytebuf.slice()`**和 `Unpooled.wrappedBuffer()` 的逻辑正好相反**,`ByteBuf.slice()`**是将一个 ByteBuf 对象切分成多个共享同一个底层存储的 ByteBuf 对象**。 2. 假如我们有一份完整的 HTTP 数据,可以通过 `slice()` 方法切分获得 `header` 和 `body` 两个 ByteBuf 对象,对应的内容分别为 `header` 和 `body`,实现方式如下: ```java ByteBuf header = httpBuf.slice(0, 6); ByteBuf body = httpBuf.slice(6, 4); ``` **通过 `slice()` 切分后都会返回一个新的 ByteBuf 对象**,而且**新的对象有自己独立的 `readerIndex`**、`writerIndex`**索引**,如下图所示,由于**新的 ByteBuf 对象与原始的 ByteBuf 对象数据是共享的**,所以**通过新的 ByteBuf 对象进行数据操作也会对原始 ByteBuf 对象生效**: 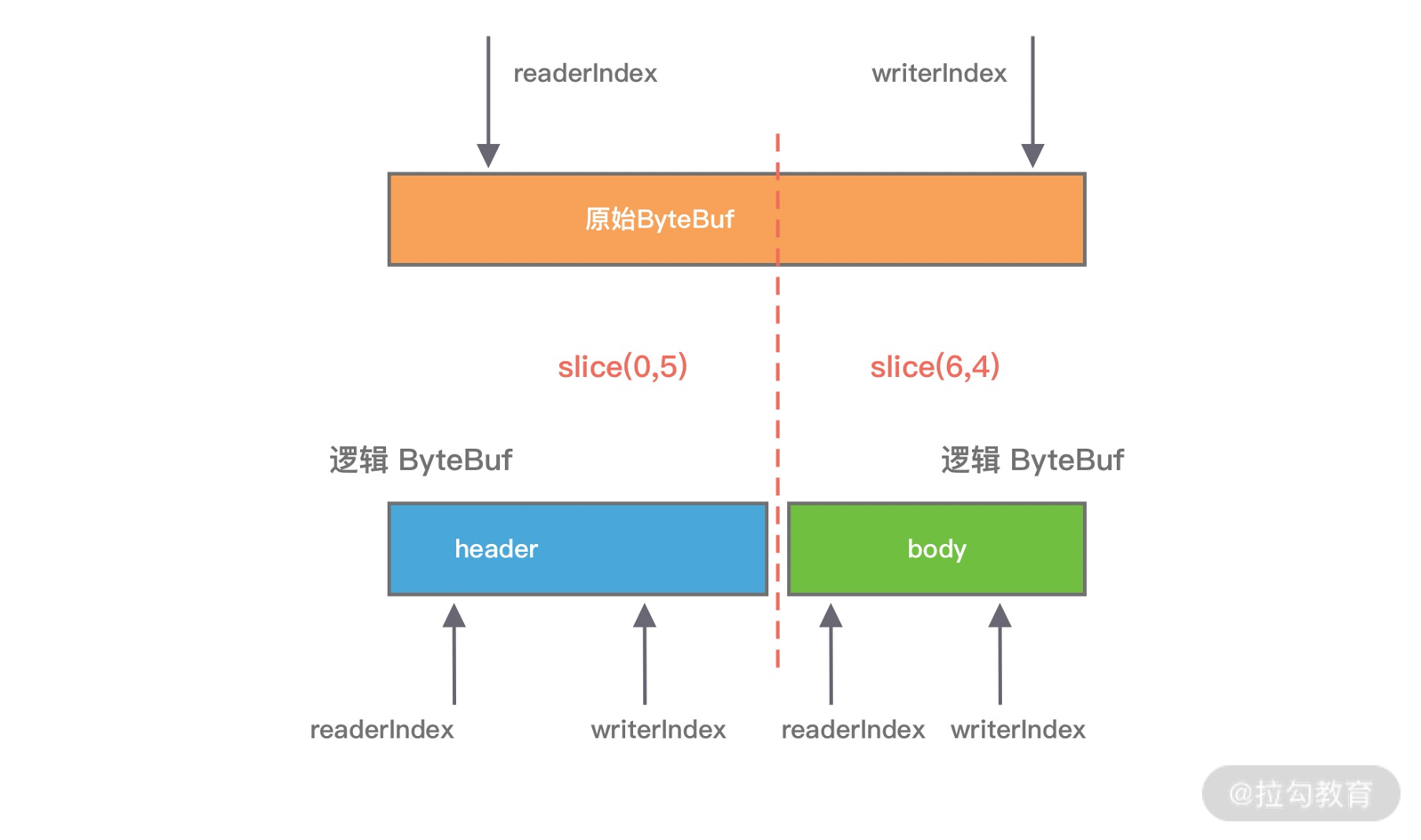 ##### 5.5.2.5 文件传输 FileRegion 1. Netty**使用 FileRegion 实现文件传输的零拷贝**,**默认实现类是 DefaultFileRegion**,**通过 DefaultFileRegion 将文件内容写入到 NioSocketChannel**,**FileRegion 其实就是对 FileChannel 的包装**,**并没有什么特殊操作**,**底层使用的是 JDK NIO 中的 `FileChannel.transferTo()` 方法实现文件传输**,所以 FileRegion**是操作系统级别的零拷贝**,**对于传输大文件会很有帮助**: 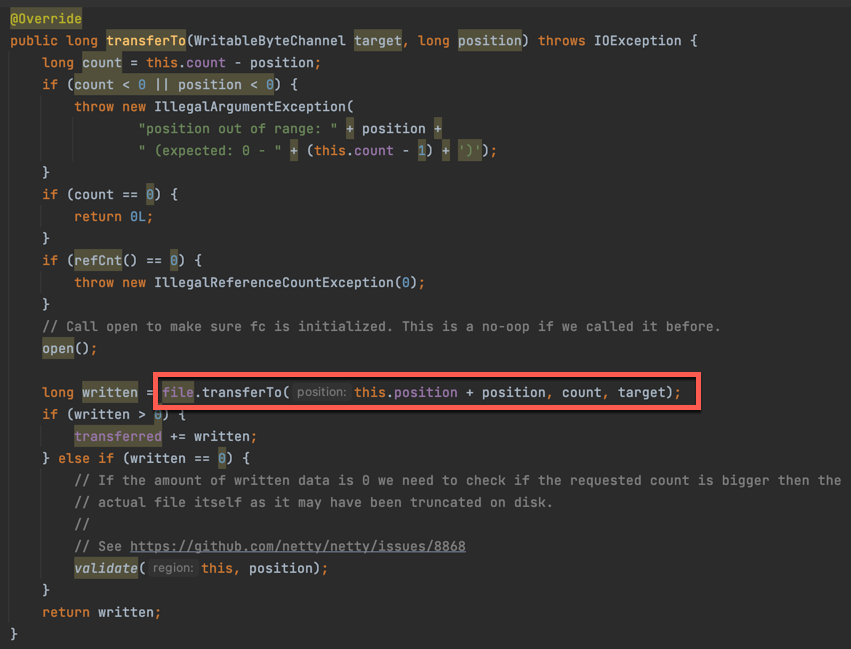 ## 参考文献 1. [03 如何自己实现一个 RPC 框架?](https://www.yuque.com/books/share/b7a2512c-6f7a-4afe-9d7e-5936b4c4cab0/hc6nzg) 2. 《Netty 权威指南 第 2 版》 3. [阿里大牛总结的 Netty 最全常见面试题,面试再也不怕被问 Netty 了](https://zhuanlan.zhihu.com/p/148726453)。 4. [offer 快到碗里来-Netty 核心面试题 15 连问](https://www.nowcoder.com/discuss/648088)。 5. [(卷一) Netty 介绍和应用场景](https://juejin.cn/post/6882545468266512398)。 6. [16 IO 加速:与众不同的 Netty 零拷贝技术](http://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/Netty%20%E6%A0%B8%E5%BF%83%E5%8E%9F%E7%90%86%E5%89%96%E6%9E%90%E4%B8%8E%20RPC%20%E5%AE%9E%E8%B7%B5-%E5%AE%8C/16%20%20IO%20%E5%8A%A0%E9%80%9F%EF%BC%9A%E4%B8%8E%E4%BC%97%E4%B8%8D%E5%90%8C%E7%9A%84%20Netty%20%E9%9B%B6%E6%8B%B7%E8%B4%9D%E6%8A%80%E6%9C%AF.md)。
ricear
2021年8月26日 14:59
©
BY-NC-ND(4.0)
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码